Understanding CLIP embeddings
A quick oveview of OpenAI's CLIP embeddings
Summary
-
Paper from OpenAI published in ICML 2021
-
Using symmetric contrastive loss
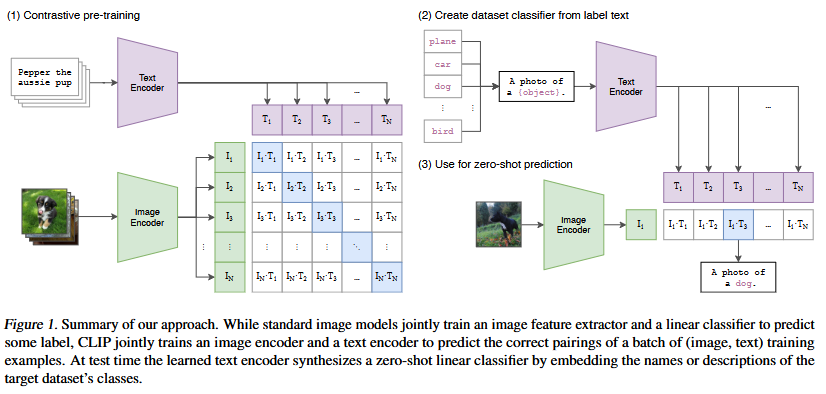
CLIP stands for Contrastive Language-Image Pretraining to train an embedding model over a large datset of 400M image-text pairs yields good embeddings. - Simplified the ConVIRT
architecture. - Created a new dataset of 400M datapoints.
Approach

Proposed Dataset
The paper doesn’t seem to give any details on how this dataset was constructed. It simply mentions that they “searched”
The base query list
this is the 500K terms list? is all words occurring at least 100 times in the English version of Wikipedia. This is augmented with bi-grams with high pointwise mutual information as well as the names of all Wikipedia articles above a certain search volume. Finally all WordNet synsets not already in the query list are added